Solution Evaluation: Spreadsheets
- 4 minutes read - 645 wordsSpreadsheets
Scoring
- Permit cycles (1)
- Permit calculated attributes (1)
- Changeset support (0)
- Schema changes are easy and cascade easily (0)
- Self-Documenting (0)
- Data can be delivered natively in a variety of views (0)
- Data is readily accessible to non-technical staff (2)
- Data is readily updated by non-technical staff (2)
- Price (3)
Total: 9
When considering a data modeling question, one will rarely go wrong by opting for a simple spreadsheet as a first step toward a solution. After nearly 40 years of ubiquity, the low cost and near-universal comprehension of the UI/UX metaphors provide spreadsheets a compelling advantage.
Despite these advantages, a spreadsheet is unable to provide good controls in modeling the accounting’s complexity. Unlike a programming language, error detection or incorrect modeling can’t trigger errors / provide guidance in a sufficiently robust fashion. In fact, a UI anti-pattern of spreadsheets is the false sense of confidence they inspire as has been researched in “A Pilot Study Exploring Spreadsheet Risk in Scientific Research” et al.
Consequently, everyone who collaborates using the spreadsheet must understand the “theory of the program” of this particular spreadsheet, a murky and ill-defined abstraction. Those who don’t understand which sheets are implied read-only or which cells are to be calculated from a chain of formulae results are liable to make an error. Even worse, if their errors are not caught by other collaborators, newer collaborators may “enshrine” their error(s) and make an incorrect behavior standard. While some data validation controls exist in sheets, they are far less robust than what code can provide and under-powered to the inherent complexity of an accounting.
The driving flaw of spreadsheets is their lack of ability to enforce referential integrity. Over time, their inherent design will drive the accounting into being an unmanageable and increasingly unusable mess. In the detailed section below, I demonstrate this using Google Sheets.
Extended demonstration of difficulties with integrity when building an accounting in a spreadsheet.
For example, consider a simple spreadsheet to-do list for a team. If we don’t
want to repeat data, we have a sheet called TodoList and a sheet called
_TeamMember_Enumeration. Here we use the _ prefix as a convention to
suggest that _TeamMember_Enumeration is a “system” sheet.
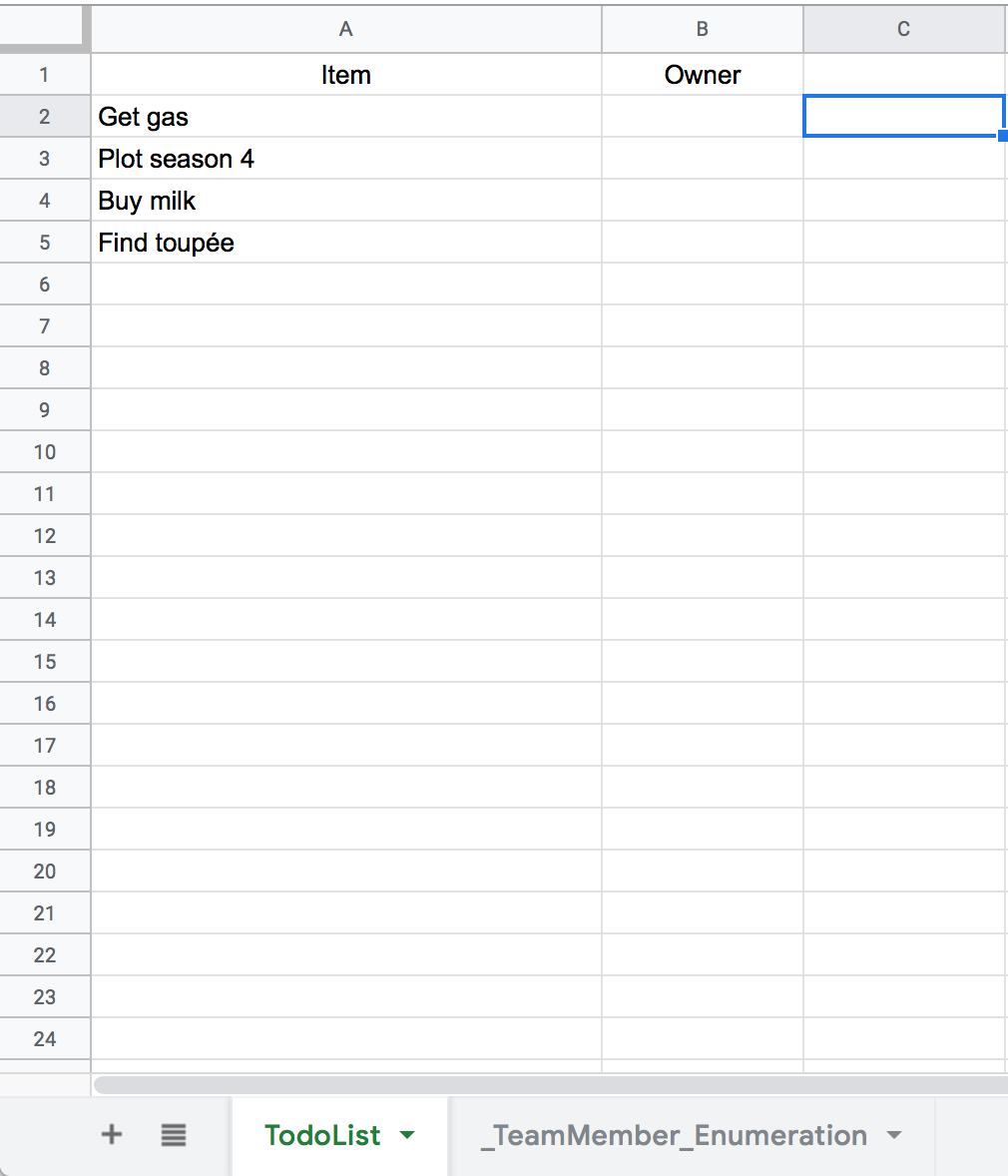
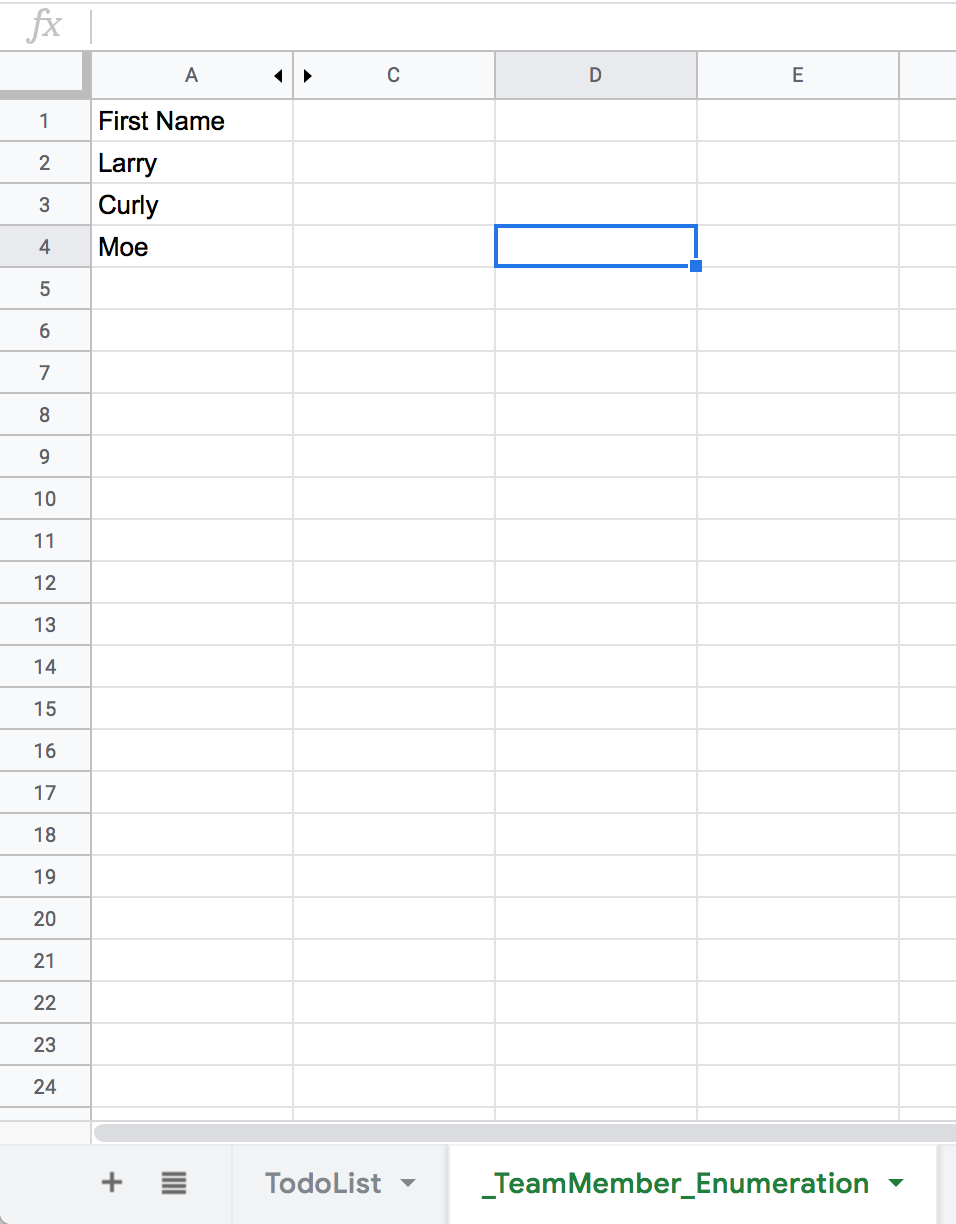
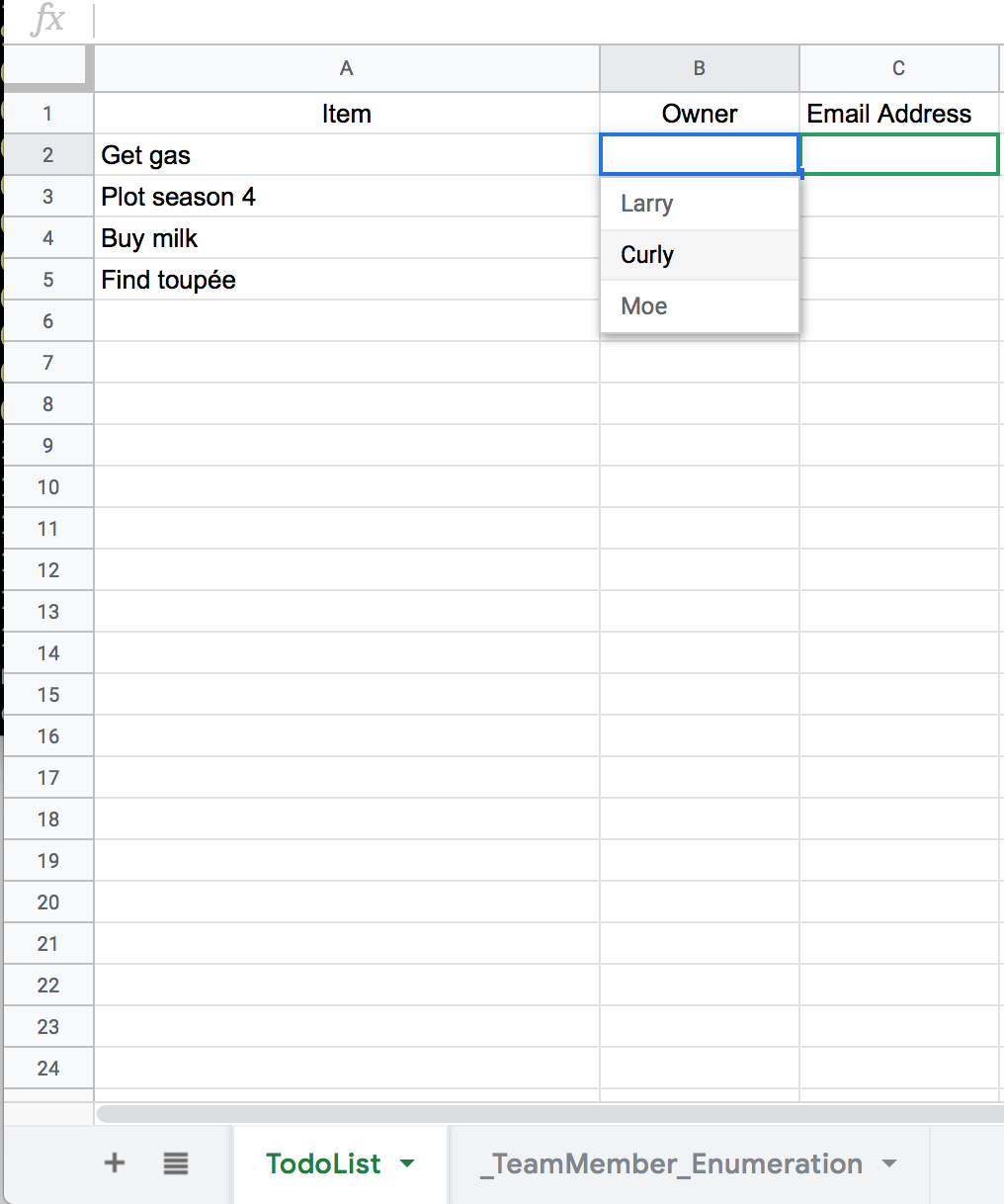
In order to constrain the values in the “Owner” column to only those names
present in the _TeamMember_Enumeration, we have to use this glorious
interface:
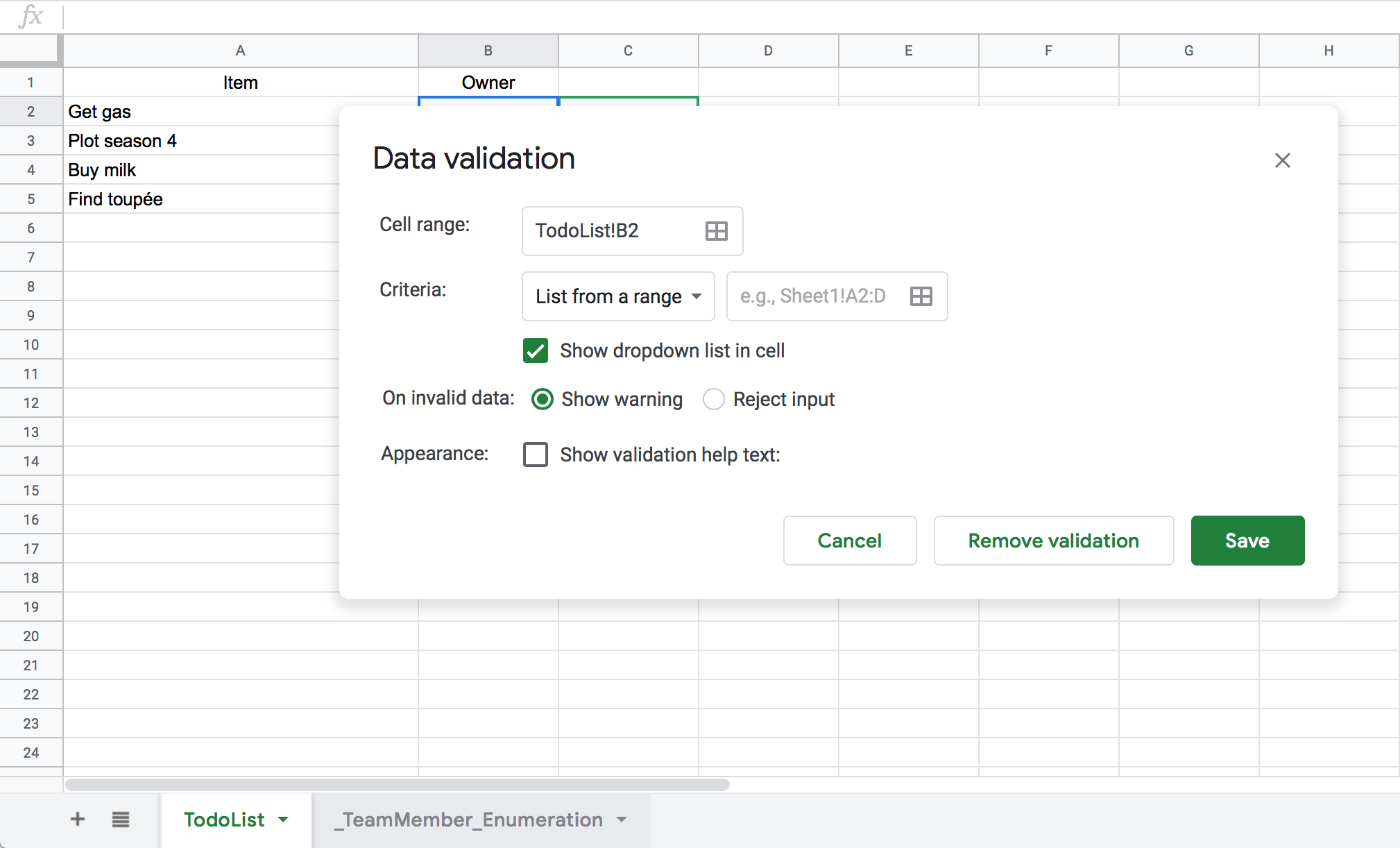
Yeow. Not exactly the easiest interface, but tolerable.
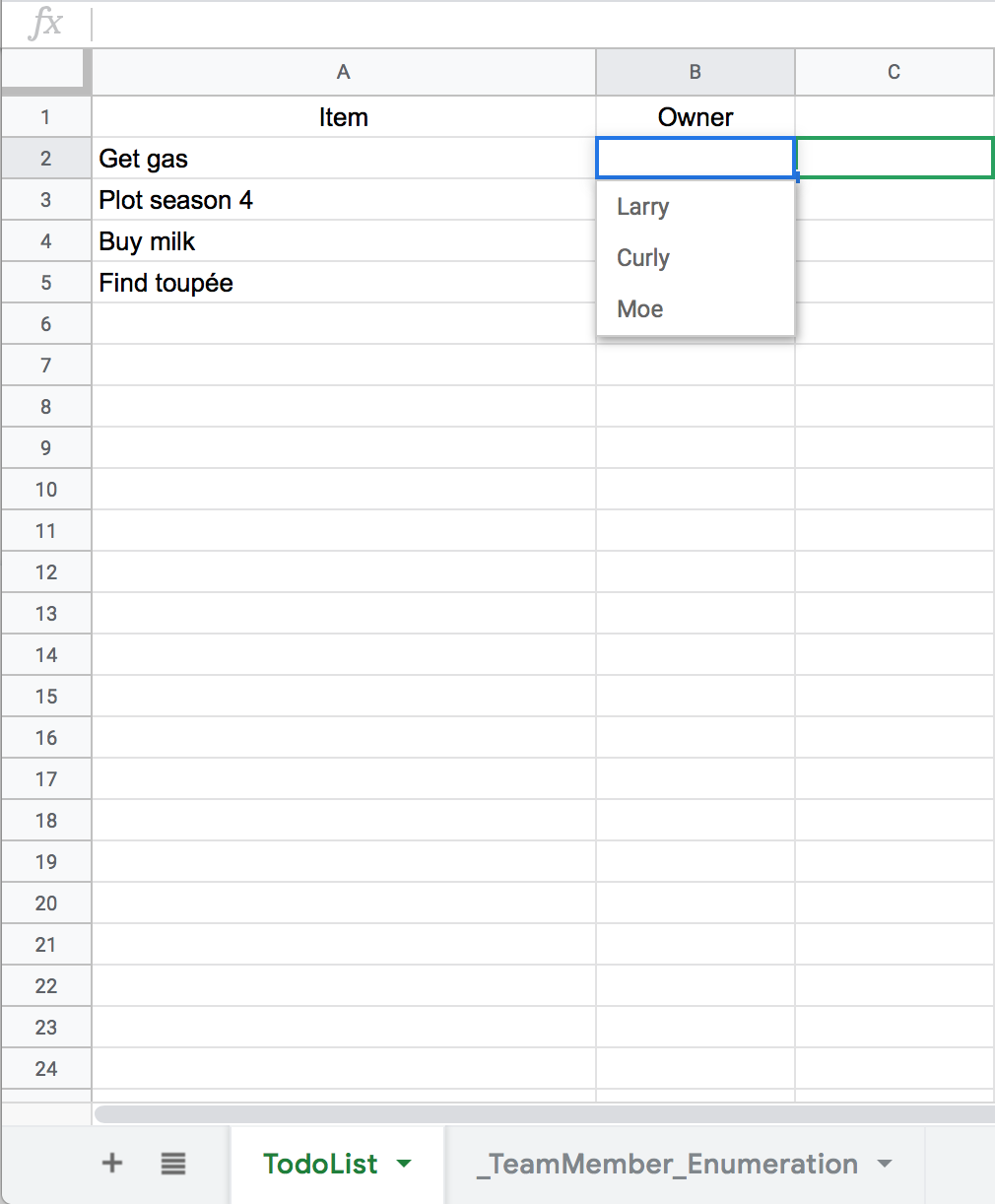
For projects that don’t tend to grow, this is probably a reasonably good data management solution. But it starts to fall apart when we start trying to add fairly simple changes.
Suppose we want to show each task owner’s email address with the item. Adding the email address column is easy:
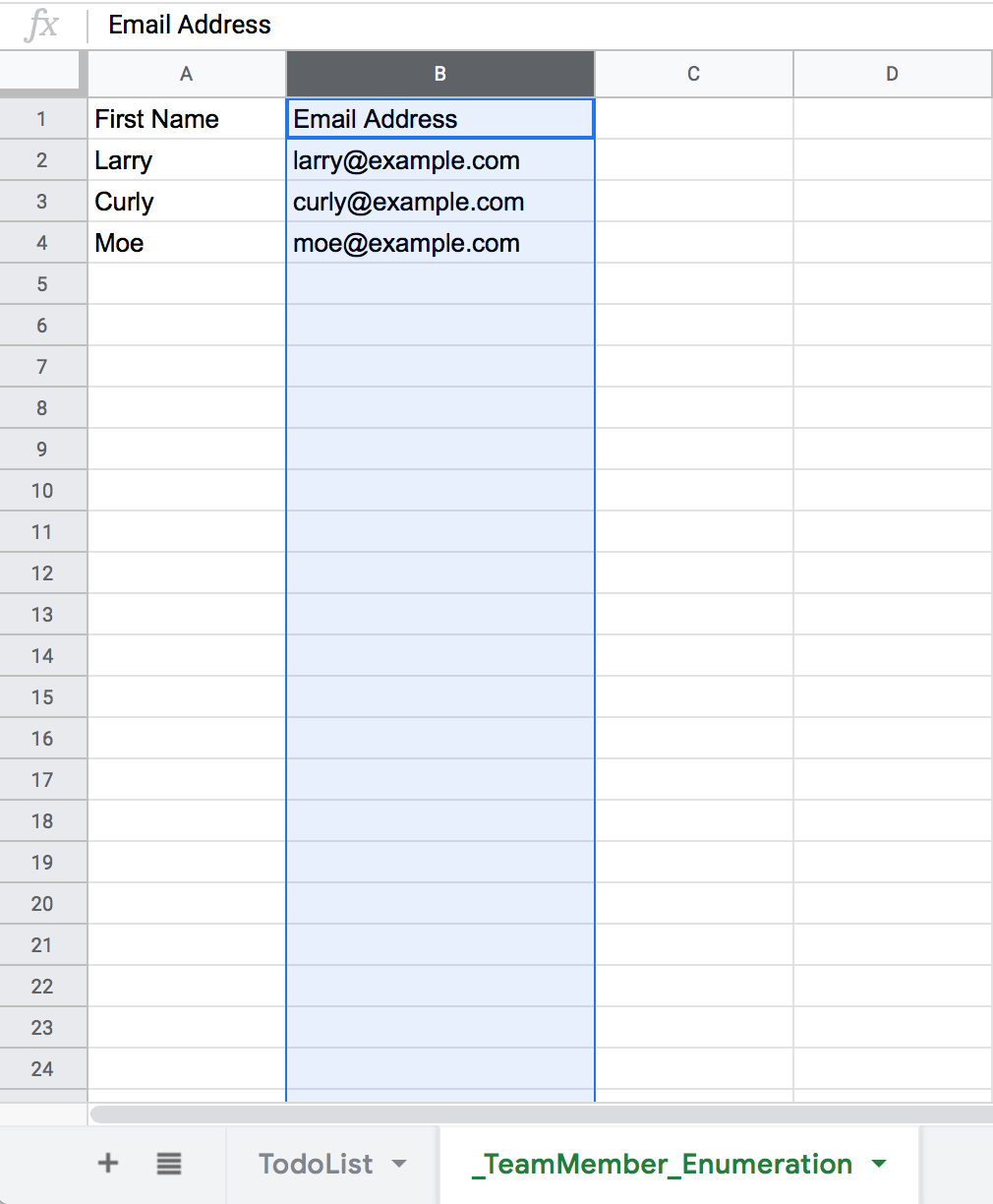
Implicitly, we’re creating records in our _TeamMember_Enumeration sheet in
a way that’s very suggestive of a database table. But now comes the challenge,
how do we express the Owner record’s email address such that when we change
that field, the email address automatically updates?
We could, conceivably, (ab-?)use the formula system or pivot table features within the spreadsheet to get something like this working, but I believe the point is sufficiently made. Spreadsheets aren’t designed to be databases.
ASIDE: I suppose this is the reason Microsoft Office, back in my day, shipped both Access as well as Excel. One is a lightweight database with a custom interface builder; the other, a spreadsheet.
While this example had successful UI/UX, it fails in terms of facilitating clean data. In the next detailed review, we’ll do the same exercise with a database and see the failures reverse position.
Conclusion
Given these weaknesses and that a database seems to have a design that helps prevent these weaknesses, maintaining a database would seem to be the recommended path. This choice, however, is problematic in different ways, chiefly in the capacity of user interface and user experience.
Next: Evaluating Databases